Salesforce Migration Strategy/Planning

Creating a migration strategy at first can seem like a very simple task. All you do is take data from one database and put it into another. However it can become much more complex. When assessing your strategy for loading data into Salesforce there are a few things to consider:
- The Salesforce Data Model
- The data relationships
- Is the data clean
- Data Volumes
- How you will be pulling the data from the database
- Method for loading/updating data
- Delta/True Up Process
- Identify The fields you need to value
- Automations within Salesforce
- Practice in a full sandbox
- Common Errors you will come across
Data Model
Knowing the Salesforce data model and the relationships between the data before you are loading in your data is very important. This comes in very handy with a the creation of a sequencing model/diagram. As you go through each object within the data model that you are planning to load make sure you note the object relationships/references and the type of relationship. Is the object a parent? Is the object a child? This will determine whether that data will need to be loaded before or after a given object. After going through each object this will provide the sequence of object that need to be loaded.
Example Sequence:
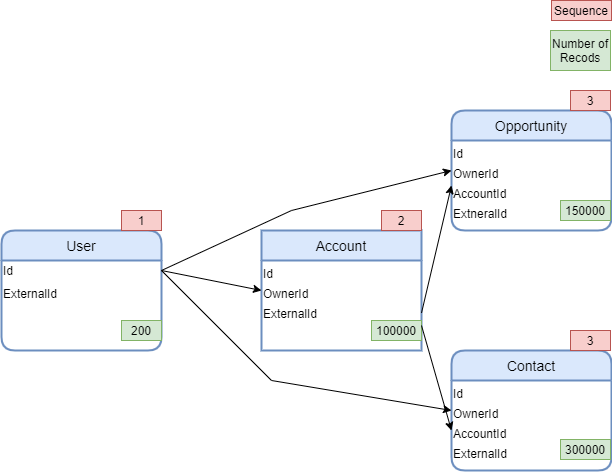
Data Relationship
As previously mentioned the type of relationship is very important to note down as well. This will help to determine the method you will be using for loading in the data. If the data has a master-detail relationship or a lookup with the option of ‘Don’t allow deletion of the lookup record that’s part of a lookup relationship.’ you will need to be aware a record locking. If the relationship has the setting ‘Clear the value of this field. You can’t choose this option if you make this field required’ record locking is less likely to occur.
Is the Data Clean
There is the very accurate saying of ‘Garbage in, Garbage out’ when migrating data don’t expect Salesforce to magically clean the data that is loaded in. Create a plan to first clean the data outside of Salesforce. If the data is in excel spreadsheets take some time to go through and identify any values that don’t line up to the new values and data expectations within Salesforce. If it is in a database or business processes are changing try to create validations/processes in the current system that will align to these new processes within Salesforce. If you are loading data with an ETL tool create mappings/translations for changing and processing that data.
Data Volumes
While creating the sequencing diagram note down the data volumes. This will help to identify if you have the correct storage size based on the number of users, the org allocation and the Salesforce record allocation. If the data is larger than the org storage limit or will hit that limit soon, create an archiving strategy along with identifying if that excess data will need to be stored somewhere (note: check to see if the archiving application needs the data in Salesforce first or if you can directly load data into the system).
Be careful of data skews, which can increase the chance of record locking and cause performance problems. If these skews can not be avoided identify the type of skew that will be caused and the appropriate methods for mitigating these effects.
How you will be pulling the data from the database
This has caused personal grief and is very important to understand before the data migration. When pulling data from a database, how will that data be pulled:
- Will all records be able to be pulled at once?
- Will multiple threads be running in parallel
- Does the database provide the ability for records to be pulled in by id ranges or does it need to be by date ranges?
- Will the single record be pulled or a hierarchy structure?
- Will the record need to be split into multiple records in Salesforce?
Each of the above questions can lead to complications if only a select number of records will be pulled at once and you have parallel threads running this can lead to record locking depending on the types of relationships with other objects. If the record needs to be split this will slow down the process and can potentially create a sequence in and of itself for loading one record before the other. If the database returns a hierarchy and that hierarchy needs to be maintained then multiple runs may need to be created in order to first create the parent and then create the children with the correct relationship.
Method for loading/updating data
How will the data be migrated? Will this be done using Bulk API or REST/SOAP api requests? Which version, v1.0 or v 2.0? Will it be JSON, CSV, or XML(only CSV can be handled by v2.0)? Will the operations be insert/update or upsert?
Identifying the method will identify the different limitation for uploading data. Bulk API has a specific set of limits and even limits within the different versions. Bulk API does not allow multiple objects inserted in one job. API Requests are based on the number of users in the org but give more flexibilities. The matrix in this video helps to show when to use different apis.
What type of operations will you be using? If there is a chance that the inserted recorded will need to be updated more than likely there won’t be access to the Salesforce Id. Consider adding and upserting(Note upserts are a longer operation as Salesforce has to determine if the record needs to be inserted or updated) with the external Id.
Delta/True Up Process
How long will the migration take, is there only certain times you can pull from the database and load into Salesforce, and will data be changing in the database while the migration is occurring? If the process will take multiple days/weeks create a strategy around how you will identify the changed records and load the changes into Salesforce.
Identify the fields you need to value
Identifying the fields that need to be valued will help to determine how you will determine the process/methods for loading in the data. Does a relationship need to be valued, if so will you use a Salesforce Id or an external Id. If you are using an external I you will need to use the upsert operation. Will the ‘Audit’ (CreatedById, CreatedDate, LastModifiedById, LastModifiedDate) fields need to be loaded? Will Records need to be updated with Inactive Owners? Both require additional permissions. Note: if you need to load in the ‘Audit’ fields be aware that these fields can only be added on INSERT if you are using an upsert with a record already loaded or an update operation and those fields are added you will receive an error and the update will fail.
Automations within Salesforce
List all automations in the org:
- Validation Rules
- Duplicate Rules
- Triggers
- Flows
- Process Builders
These can slow down the migration process if they are still on or create unintentional side effects. The recommendation is to turn them all off. If one/multiple need to be turned on make sure to flow out the exact outcomes(updates to the record, updates to children, new records) and identify if it is bulkified(can handle 200 records in a single transaction).
Test in a full sandbox
It is very important when migrating to practice in a sandbox, if you are loading large data volumes DO NOT SKIP testing in a full sandbox with the appropriate record size and the proper relationships. Skipping this step creates a very high likely hood of errors/performance issues when loading into production.
Common Errors you will come across
- UNABLE_TO_LOCK_ROW
- This error is due to record locking
- INVALID_FIELD:Foreign key external ID: xxxx not found for field xxx in entity xxxx
- This is due to upserting a record with a relationship using the external Id instead of the Salesforce Id
Checkout My New Course:
Crush It As A Salesforce Developer: Mastering Apex

Test Your Knowledge:
Try the new Salesforce Developer Quiz